tokenized-to-tree
An XProc/XSLT Library For Patching Back Tokenization/Analysis Results Into Marked-up Text
Gerrit Imsieke (@gimsieke), le-tex publishing services (@letexml)

Problems addressed / Applications
- Adding linguistic analysis information to .docx documents
- Tagging a PDF’s line and page breaks in the TEI source document
- Inserting links into tagged documents
… with a single, customizable, open-source XProc/XSLT library
Linguistic analysis of .docx files

Linguistic analysis of .docx files
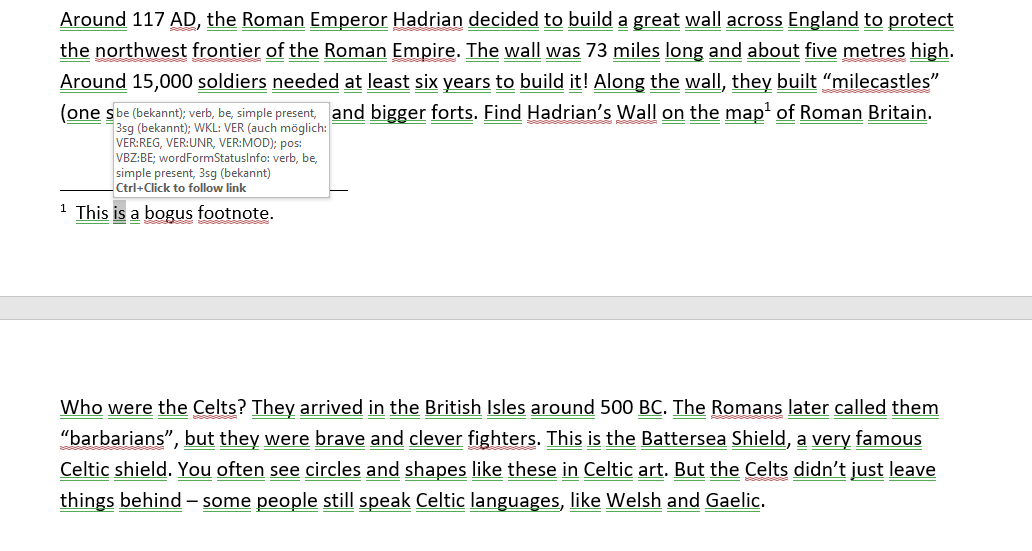
Linguistic analysis of .docx files
Tagging a PDF’s line breaks in the TEI source document
Taken from: Uwe Johnson Werkausgabe. Ein Vorhaben der
Berlin-Brandenburgischen Akademie der Wissenschaften an der Universität
Rostock

Tagging a PDF’s line breaks in the TEI source document
Taken from: Uwe Johnson Werkausgabe. Ein Vorhaben der
Berlin-Brandenburgischen Akademie der Wissenschaften an der Universität
Rostock

Tagging a PDF’s line breaks in the TEI source document
Taken from: Uwe Johnson Werkausgabe. Ein Vorhaben der
Berlin-Brandenburgischen Akademie der Wissenschaften an der Universität
Rostock

Inserting links into tagged documents
See the synthetic ttt-linking-demo repo on
Github
It links occurrences (in the paragraphs) of chapter titles to the respective chapters.
The similar real-life application (for Deutscher Apotheker Verlag) linked occurrences of an entry title to the primary entry in major reference works (thousands of pages).
→ see demo source
Inserting links into tagged documents
Step-by-step inspection of the linking scenario. Macroscopic steps:
p:xsltwith customprepare-target-list.xslttt:prepare-input(library step with 3 XSLT passes)p:xsltwith customfind-candidates.xslttt:process-paras(library step with 3 XSLT passes)ttt:merge-results(library step with 3 XSLT pass)
→ demo (diff between input and linked output is on next slide)
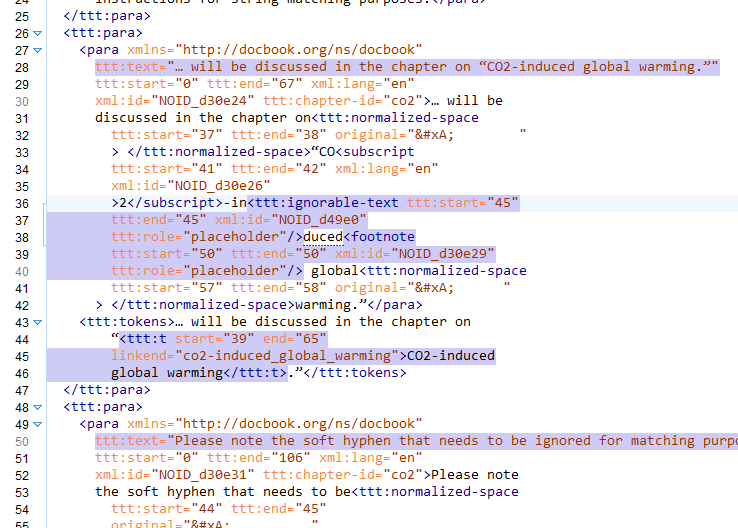
Diff
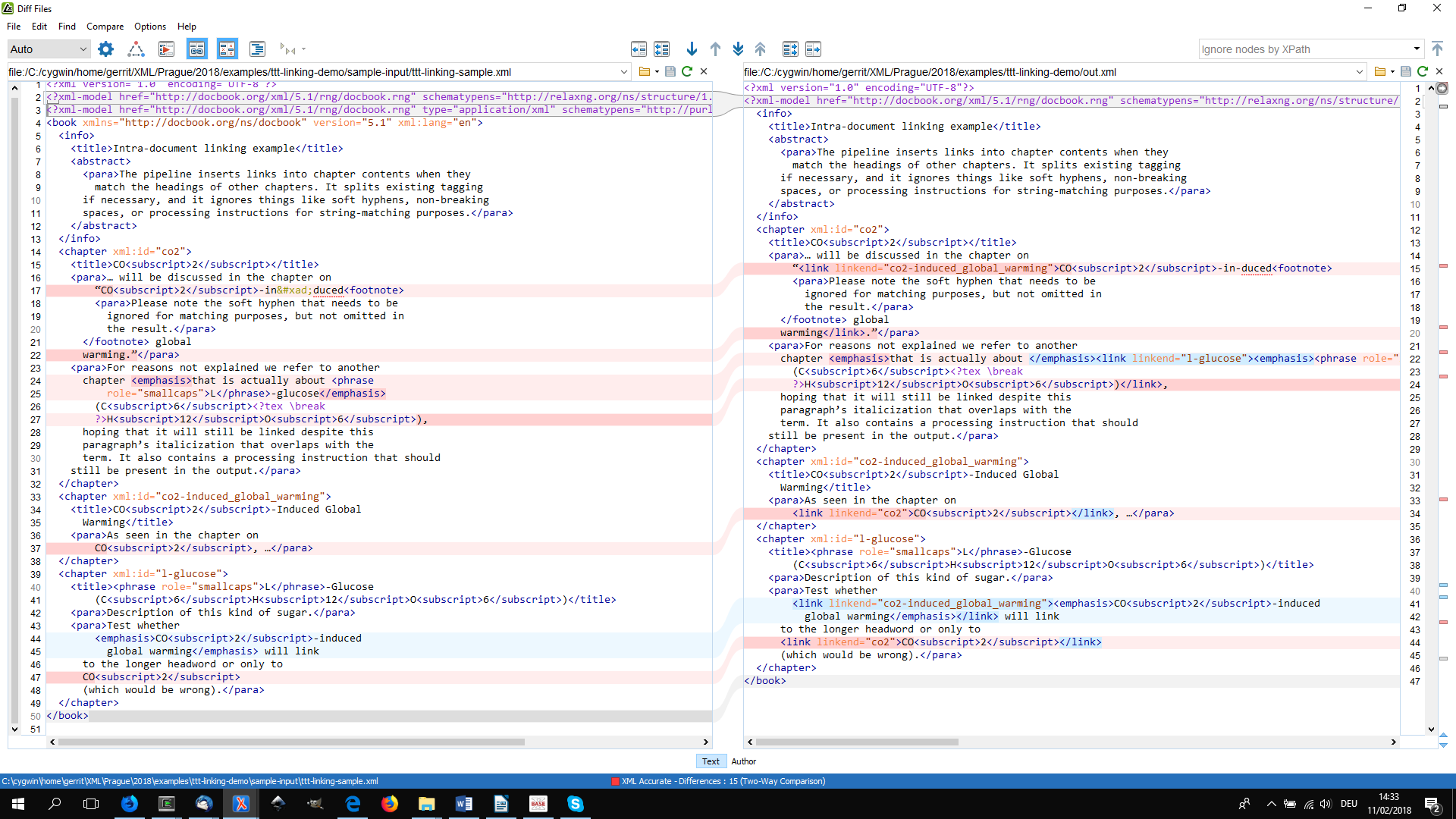
Output of the bespoke find-candidates.xsl pass
Performance Detail: Converting token start/end milestones into spanning elements
Occurs as last XSLT pass in ttt:process-paras
- “Upward projection” method for pulling up milestones to immediately beneath the paragraph
- Only then may they be connected into spanning elements
- Why is it a good idea to split up the input into paragraph-like units?
- Performance scales roughly with node count times splitting point count
- 10 paras with 20 elements and 4 milestones each ⇒ (10×20)×(10×4) = 8000 when processing as single chunk, 10×20×4 = 800 individually
Common properties of the three tasks
- Deeply nested XML
- Flat-string-based tokenization, often by regex matching
- Enriching the tokens with analysis results:
- part of speech information
- page/line numbers from a PDF
- link targets
- Merging the new token structure with the source XML
⇒ Overlapping markup
Interface of mark-linebreaks.xpl
(The PDF scenario)
- Pulling up milestones is optional; not used here
- Good showcase for multiple output ports in XProc

Details of mark-linebreaks.xpl

Advantages of XProc in orchestrating these pipelines
- Functional language
- Excellent encapsulation
- Thereby great customizability (config files or overriding XSLT on input ports)
- In contrast to other functional languages: Multiple “return values” (output ports) whose consumption
can be deferred to when they are needed (
ttt:prepare-inputon the previous slide) - Wealth of other libraries, in particular for dealing with zipped XML formats such as .docx, IDML, or EPUB (for ex. docx2hub, hub2docx)
Thank you!
Library: github.com/transpect/tokenized-to-tree
DocBook linking sample application: github.com/gimsieke/ttt-linking-demo/
Paper: archive.xmlprague.cz/2018/files/xmlprague-2018-proceedings.pdf (p. 229)